ai-tools
Image to Prompt pour ChatGPT : créez des workflows reproductibles
Découvrez comment utiliser l'image to prompt pour ChatGPT : extrayez des prompts à partir d'images, améliorez les résultats de vision et créez des workflows IA réutilisables qui vous font gagner des heures.

La plupart des gens utilisent la capacité de vision de ChatGPT de la manière la plus lente : ils téléversent une image, tapent “décris ceci,” récupèrent un paragraphe, puis repartent de zéro pour l'image suivante. Ça fonctionne, mais ça ne passe pas à l'échelle. Si vous traitez des images toute la journée — photos de produits, références de design, visuels de campagne, créations concurrentes — cette approche au coup par coup consomme discrètement des heures et produit des résultats incohérents.
L'image to prompt pour ChatGPT est la solution. Au lieu de requêtes improvisées, vous construisez un système reproductible : vous extrayez des prompts structurés à partir d'images, vous les injectez dans ChatGPT avec un modèle d'instruction cohérent, et vous réutilisez les résultats dans tout votre travail. Ce guide vous montre comment concevoir ce workflow de A à Z — le vocabulaire auquel la vision de ChatGPT répond réellement, les modèles qui rendent les résultats reproductibles, et la logique de décision pour savoir quand automatiser plutôt que rédiger à la main. Il est écrit pour les personnes qui font cela en volume et qui veulent un système, pas un tour de passe-passe.
Réponse rapide
L'image to prompt pour ChatGPT est la pratique consistant à convertir une image en un prompt textuel structuré et réutilisable — soit en dirigeant le propre modèle de vision de ChatGPT, soit en utilisant d'abord un outil d'image to prompt dédié — afin de pouvoir analyser, décrire ou recréer des visuels de façon cohérente et à grande échelle. Le bénéfice principal est la reproductibilité : une structure de prompt standardisée produit des résultats comparables sur de nombreuses images, au lieu d'une réponse différente à chaque fois.
Table des matières
- Qu'est-ce que l'image to prompt pour ChatGPT ?
- Comment ChatGPT comprend les images
- Pourquoi la rédaction manuelle de prompts échoue à grande échelle
- Le workflow professionnel
- Exemples de workflows réels
- Cas d'usage par équipe
- Modèles de prompts (copier-coller)
- Le framework REFINE pour de meilleurs prompts
- Techniques professionnelles pour de meilleurs prompts ChatGPT
- Les erreurs qui réduisent la qualité des prompts
- FAQ
- Points clés à retenir
Qu'est-ce que l'image to prompt pour ChatGPT ?
L'image to prompt pour ChatGPT désigne tout workflow qui transforme une entrée visuelle en un prompt textuel structuré que vous pouvez utiliser dans ChatGPT. Il existe deux façons de procéder, et comprendre la distinction est le fondement de tout le reste :
Extraction directe. Vous téléversez l'image dans ChatGPT lui-même et vous demandez à son modèle de vision de la décrire dans un format spécifique et structuré. ChatGPT réalise l'analyse et la mise en forme en une seule étape.
Extraction assistée par outil. Vous passez d'abord l'image dans un outil d'image to prompt dédié — comme l'outil Image to Prompt d'Avriro — qui renvoie un prompt structuré et propre. Vous amenez ensuite ce prompt dans ChatGPT pour le raffinement, l'expansion ou des tâches en aval.
Aucune n'est universellement meilleure ; elles conviennent à des situations différentes, que nous détaillons dans l'arbre de décision plus loin. Ce qu'elles ont en commun, c'est l'objectif : remplacer des requêtes vagues et ponctuelles par un artefact structuré et réutilisable. Cet artefact est l'unité d'un workflow évolutif.
| Directe (vision ChatGPT) | Assistée par outil | |
|---|---|---|
| Vitesse par image | Plus lente (vous rédigez un prompt à chaque fois) | Plus rapide (extraction en un clic) |
| Cohérence | Dépend de votre instruction | Élevée, sortie standardisée |
| Contrôle | Total — vous dirigez le format | Préréglé, puis raffiné dans ChatGPT |
| Idéal pour | Analyse nuancée et ponctuelle | Gros volume, tâches reproductibles |
Comment ChatGPT comprend les images
Pour construire un bon workflow, vous avez besoin d'un modèle mental opérationnel de ce qui se passe quand ChatGPT “voit” une image. Sa capacité de vision repose sur un modèle multimodal qui traite ensemble les informations visuelles et textuelles, comme le décrit la documentation d'OpenAI. En pratique, trois conséquences découlent de son fonctionnement :
Il lit globalement, pas seulement objet par objet. ChatGPT ne se contente pas de lister des objets ; il interprète les relations, le style, l'ambiance et le contexte. C'est pourquoi il excelle à décrire pourquoi une image dégage une certaine impression — et pourquoi vos instructions devraient demander une interprétation, pas un simple inventaire.
Il suit votre cadrage. La même image produit des sorties radicalement différentes selon la façon dont vous formulez la demande. “Liste les objets” et “décris l'éclairage et la composition sous forme de brief photographique” donnent des analyses différentes de l'image identique. Votre instruction est une lentille.
Il peut combler les vides, et il le fera. Comme tous les modèles vision-langage, ChatGPT infère parfois des détails qui ne sont pas strictement présents — un matériau plausible, un décor supposé. C'est utile pour l'expansion créative, mais c'est un risque pour une description exacte, ce qui explique pourquoi la vérification est une étape permanente de tout workflow sérieux.
L'implication stratégique : la vision de ChatGPT ne vaut que par la structure que vous lui donnez. Une demande vague produit une réponse vague et non reproductible. Une instruction structurée produit une réponse structurée et réutilisable. C'est cette structure que construit le reste de ce guide.
Pourquoi la rédaction manuelle de prompts échoue à grande échelle
Rédiger chaque prompt à la main fonctionne très bien pour une image. Cela s'effondre de façon prévisible dès que le volume entre en jeu. Voici pourquoi :
- Incohérence. Dix prompts rédigés à la main produisent dix formats de sortie différents, rendant les résultats impossibles à comparer ou à traiter par lots en aval.
- Charge cognitive. Rédiger à chaque fois une instruction détaillée et experte à partir de zéro est réellement épuisant, et la qualité se dégrade à mesure que la fatigue s'installe au fil d'une longue session.
- Vocabulaire perdu. Les bons termes descriptifs — direction de l'éclairage, angle de caméra, matériau, composition — sont difficiles à retrouver sur commande, si bien que les prompts manuels tendent à omettre précisément les détails qui comptent le plus.
- Aucune réutilisabilité. Un prompt ponctuel tapé dans une fenêtre de chat puis oublié ne peut être ni réutilisé, ni versionné, ni partagé avec une équipe.
- Coût en temps. À grande échelle, les minutes par image s'accumulent. Traiter 100 images à la main est un problème d'un tout autre ordre que d'en traiter une seule.
Le schéma est le même que celui qui apparaît dans tout le travail avec l'IA : le goulot d'étranglement n'est pas le modèle, c'est la capacité de l'humain à fournir de façon cohérente une bonne structure. Systématiser cette structure — via des modèles et des outils d'extraction — est ce qui transforme un modèle performant en un workflow productif. Si vous débutez sur l'étape d'extraction elle-même, les fondamentaux de la conversion d'une image en prompt IA constituent un bon point de départ.
Le workflow professionnel
Voici le système reproductible. Il comporte cinq étapes, et son but unique est de convertir un visuel en un artefact standardisé et réutilisable plutôt qu'en une réponse jetable.
Étape 1 — Standardisez votre entrée. Décidez du format que vous voulez avant de toucher à une image. Brief en langage naturel ? JSON structuré ? Liste de tags ? Un format cible cohérent est ce qui rend les sorties comparables.
Étape 2 — Extrayez. Convertissez l'image en un prompt de base. Pour un gros volume, un outil dédié produit un brouillon propre et cohérent en un clic. Pour des cas nuancés et ponctuels, adressez directement la demande à la vision de ChatGPT avec votre instruction standard.
Étape 3 — Raffinez dans ChatGPT. Amenez le prompt de base dans ChatGPT et utilisez-le comme matière première — développez-le, adaptez-le à un modèle cible, transformez-le en brief, ou générez des variations. C'est là que la force linguistique de ChatGPT apporte le plus de valeur.
Étape 4 — Vérifiez. Confrontez la sortie à l'image source. Supprimez tout détail inféré qui n'est pas réellement présent, et ajoutez tout ce que l'extraction a manqué. Ne sautez jamais cette étape — c'est le garde-fou contre les détails hallucinés.
Étape 5 — Stockez et réutilisez. Enregistrez le prompt finalisé dans une bibliothèque avec une étiquette claire. Réutilisez-le et remixez-le. La cohérence au sein d'un projet vient de la réutilisation de structures éprouvées, et non de la réécriture à chaque fois.

La raison pour laquelle cela fonctionne, c'est que le système sépare l'analyse (mieux gérée par un modèle de vision ou un outil d'extraction) du travail linguistique (mieux géré par ChatGPT) et du jugement (le vôtre). Chaque étape fait une seule chose bien, ce qui rend l'ensemble du système fiable et suffisamment rapide pour tourner en volume.
Exemples de workflows réels
Ce sont des démonstrations illustratives montrant comment le raisonnement s'applique — pas des captures d'écran ni des études de cas mesurées.
Exemple 1 — Descriptions de produits e-commerce à grande échelle. Une équipe e-commerce a besoin de descriptions cohérentes et optimisées pour le SEO pour des centaines de photos de produits. Le workflow : extraire un prompt structuré de chaque image de produit, puis le transmettre à ChatGPT avec une instruction fixe — “À partir de cette description, rédige un texte produit de 60 mots dans la voix de notre marque, en mettant l'accent sur le matériau et le cas d'usage.” Parce que chaque image entre dans le même pipeline, toutes les sorties partagent format et ton. Cela se marie naturellement avec un générateur de fiches produits pour l'étape de publication.
Exemple 2 — Briefs de références de design. Un designer rassemble des références de mood board et a besoin que chacune soit traduite en un brief créatif clair. Le workflow : extraire un prompt capturant le style, la palette et la composition, puis demander à ChatGPT de le reformater en un brief structuré avec des sections pour l'ambiance, la couleur et la mise en page. Le résultat est un modèle de brief cohérent pour chaque référence, prêt à être transmis à une équipe ou à un générateur.
Exemple 3 — Adaptation de prompt entre modèles. Un créateur veut recréer le style d'une image dans un autre générateur. Le workflow : extraire la description de base, puis demander à ChatGPT de l'adapter au système cible — par exemple, en la convertissant dans le style concis et pondéré par virgules que préfère Midjourney. Notre guide sur l'image to prompt pour Midjourney couvre en profondeur cette adaptation spécifique à la cible.
Exemple 4 — Analyse créative concurrentielle. Une agence marketing examine les visuels publicitaires concurrents. Le workflow : extraire des descriptions structurées de chacun, puis demander à ChatGPT de les comparer selon des dimensions fixes — stratégie de couleur, composition, tonalité émotionnelle — produisant une grille d'analyse standardisée plutôt que des impressions vagues.
Le fil conducteur : dans chaque cas, une extraction standardisée en amont est ce qui rend la sortie de ChatGPT en aval cohérente et réutilisable.
Cas d'usage par équipe
- Designers — traduire des références en briefs ; maintenir la cohérence de style sur une série.
- Équipes e-commerce — générer par lots des descriptions de produits et des textes alternatifs à partir de photos, avec une structure uniforme.
- Créateurs de contenu — transformer l'inspiration visuelle en bibliothèques de prompts réutilisables pour une production reproductible.
- Agences marketing — standardiser l'analyse créative concurrentielle et les briefs visuels de campagne pour tous les clients.
- Prompt engineers — construire et versionner des modèles de prompts ; systématiser l'extraction comme une étape de pipeline.
- Passionnés d'IA — apprendre le vocabulaire descriptif en lisant et en éditant des extractions structurées.
Modèles de prompts (copier-coller)
Ce sont des modèles d'instruction originaux et réutilisables. Collez votre description extraite là où c'est indiqué.
Modèle 1 — Brief d'image structuré
Analyse la description d'image suivante et renvoie un brief structuré avec ces sections : Sujet, Décor, Éclairage, Composition, Palette de couleurs, Ambiance, Style. Sois précis et concis. Description : [PASTE].
Modèle 2 — Texte produit à partir d'une image
À partir de cette description de produit, rédige un texte produit de [WORD COUNT] mots sur un ton [BRAND VOICE]. Mets en avant le matériau, le cas d'usage et un bénéfice marquant. Description : [PASTE].
Modèle 3 — Adaptation entre modèles
Convertis cette description en un prompt concis, séparé par des virgules, optimisé pour [TARGET MODEL]. Place le sujet et le style en tête ; garde-le sous [N] mots. Description : [PASTE].
Modèle 4 — Générateur de variations
À partir de cette description, génère 5 variations de prompt qui conservent le même sujet et le même style, mais font varier l'éclairage, l'angle de caméra et l'ambiance. Description : [PASTE].
Modèle 5 — Contrôle d'exactitude
Compare cette description à l'image jointe. Liste tous les détails de la description qui ne sont PAS visibles dans l'image, ainsi que tous les détails visibles que la description a manqués. Description : [PASTE].
Le Modèle 5 est celui que les gens sautent et ne devraient pas — il rend opérationnelle l'étape de vérification.
Le framework REFINE pour de meilleurs prompts
L'extraction vous donne un brouillon. Ce cadre — appelez-le le cadre R-E-F-I-N-E — est la façon de transformer un brouillon grossier en un prompt de haute qualité et réutilisable. C'est une structure originale que vous pouvez appliquer à n'importe quelle description extraite.
- R — Supprimer les détails hallucinés ou inexacts (vérifiez par rapport à la source).
- E — Accentuer les éléments qui comptent le plus pour votre objectif ; placez-les en tête.
- F — Formater pour la destination (brief, tags, prompt pondéré par virgules, JSON).
- I — Itérer une variable à la fois pour isoler l'effet de chaque changement.
- N — Nommer et enregistrer le prompt finalisé dans votre bibliothèque.
- E — Évaluer la sortie par rapport à votre intention, et affiner le modèle si nécessaire.

La valeur du cadre, c'est qu'il est reproductible. Une fois vos modèles et votre processus REFINE en place, traiter la centième image est aussi rapide et cohérent que la première — ce qui est tout l'intérêt d'un workflow.
Techniques professionnelles pour de meilleurs prompts ChatGPT
- Standardisez la sortie en JSON pour les pipelines. Si vos extractions alimentent un logiciel, demandez à ChatGPT de renvoyer du JSON strict avec des clés fixes. Une structure prévisible rend l'automatisation en aval triviale.
- Construisez une bibliothèque de modèles, pas des prompts ponctuels. Versionnez vos modèles d'instruction comme vous versionneriez du code. La réutilisation bat la réinvention.
- Séparez l'analyse de la génération. Utilisez l'extraction/vision pour ce qui se trouve dans l'image et ChatGPT pour ce qu'il faut en faire. Les mélanger dans un seul prompt vague dégrade les deux.
- Placez les termes saillants en tête. L'extraction comme ChatGPT pondèrent davantage le contenu placé au début ; commencez par ce qui compte.
- Tenez une liste “négative”. Notez les détails que les outils hallucinent couramment pour votre type d'image, et élaguez-les par défaut.
- Adaptez le style d'extraction à la destination. Langage naturel pour les briefs et Midjourney ; tags pour SDXL. Ne forcez pas un seul format partout.
- Consultez les fondamentaux. Pour des principes de prompt-craft valables sur tous les modèles, le Prompt Engineering Guide communautaire et les conseils de prompting d'OpenAI sont des références solides.
Les erreurs qui réduisent la qualité des prompts
- Traiter l'extraction comme finale. Le brouillon est de la matière première, pas un prompt finalisé. Raffinez et vérifiez toujours.
- Sauter la vérification. Les détails hallucinés se propagent dans tout votre workflow si vous ne les attrapez pas à la source.
- Instructions incohérentes. Une formulation différente par image détruit la comparabilité qui fait la valeur d'un workflow. Standardisez.
- Surcharger un seul prompt. Demander à ChatGPT d'analyser, de réécrire et d'adapter tout en même temps produit une sortie confuse. Séparez les étapes.
- Aucun système de stockage. Des prompts tapés puis oubliés ne peuvent pas s'accumuler en une bibliothèque. Enregistrez les bons.
- Mauvais format pour la destination. Une description de type brief forcée dans un générateur basé sur des tags sous-performe. Adaptez le format à la cible.
La méta-erreur derrière toutes celles-ci : optimiser une seule sortie au lieu de construire un système. Le gain du travail d'image to prompt n'est pas une belle description — c'est un processus reproductible qui produit de belles descriptions de façon fiable.
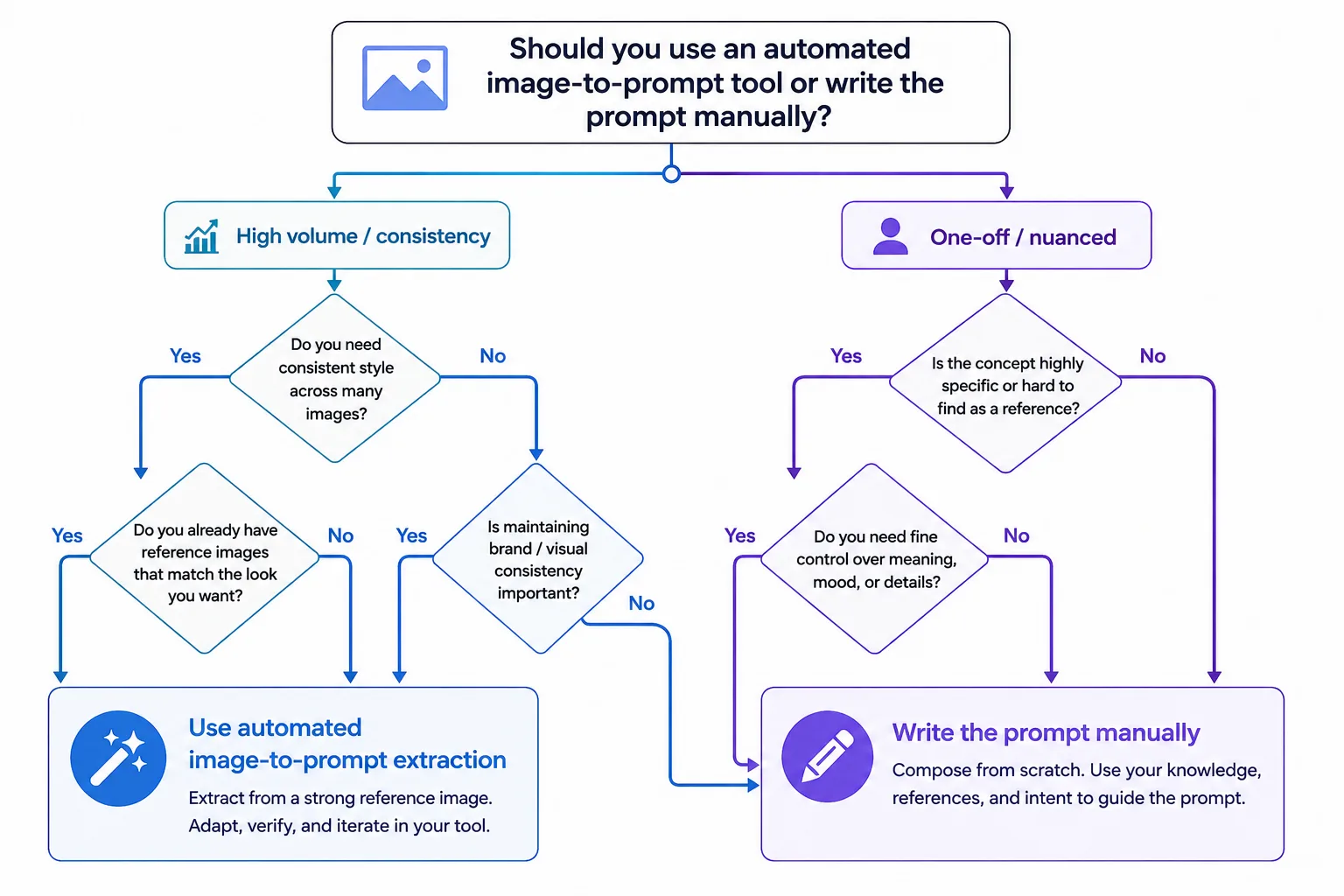
FAQ
Qu'est-ce que l'image to prompt pour ChatGPT ?
C'est la pratique consistant à convertir une image en un prompt textuel structuré et réutilisable — soit en dirigeant le modèle de vision de ChatGPT, soit en utilisant d'abord un outil d'extraction dédié — afin de pouvoir analyser ou recréer des visuels de façon cohérente et à grande échelle.
ChatGPT peut-il générer un prompt à partir d'une image ?
Oui. Téléversez une image et demandez-lui de décrire l'image dans un format structuré spécifique. La qualité dépend fortement du degré de structuration de votre instruction.
Dois-je utiliser ChatGPT directement ou un outil dédié ?
Utilisez ChatGPT directement pour une analyse nuancée et ponctuelle où vous voulez un contrôle total. Utilisez un outil dédié pour le gros volume et la cohérence, puis raffinez dans ChatGPT. L'arbre de décision ci-dessus le détaille.
La vision de ChatGPT hallucine-t-elle des détails ?
Parfois, oui — comme tous les modèles vision-langage, il peut inférer des détails absents de l'image. C'est pourquoi une étape de vérification est essentielle dans tout workflow sérieux.
Comment rendre les sorties cohérentes sur de nombreuses images ?
Standardisez votre modèle d'instruction et votre format de sortie cible, et faites passer chaque image dans le même pipeline. La cohérence vient d'un processus fixe, pas du modèle.
Puis-je l'utiliser pour l'e-commerce à grande échelle ?
Oui — c'est l'un des cas d'usage les plus forts. Extrayez des descriptions structurées, transmettez-les à ChatGPT avec une instruction fixe de voix de marque, et générez un texte produit uniforme.
Quelle est la différence entre ceci et le reverse prompt engineering ?
Ils se chevauchent. Le reverse prompt engineering signifie spécifiquement dériver le prompt qui pourrait recréer une image ; l'image to prompt pour ChatGPT est plus large, couvrant l'analyse, la description et les tâches de workflow aussi bien que la recréation.
Dois-je connaître le prompt engineering pour commencer ?
Non. Lire et éditer des extractions structurées est en soi un moyen rapide d'apprendre le vocabulaire. Les modèles proposés ici vous donnent un point de départ sans expertise préalable.
La même instruction donnera-t-elle toujours le même résultat ?
Pas à l'identique — les modèles de langage varient leur sortie. Mais un modèle cohérent produit une structure cohérente, ce qui est ce qui compte pour un workflow.
Cela peut-il alimenter des pipelines automatisés ?
Oui. Demandez à ChatGPT de renvoyer du JSON strict avec des clés fixes, et la sortie structurée peut piloter directement des logiciels en aval.
Points clés à retenir
L'image to prompt pour ChatGPT ne concerne pas vraiment une image en particulier — il s'agit de construire un système qui transforme des entrées visuelles en sorties cohérentes et réutilisables sans consumer votre temps sur chacune d'elles. Le workflow sépare l'analyse, le travail linguistique et le jugement en étapes distinctes pour que chacune soit rapide et fiable, et les modèles ainsi que le cadre REFINE rendent la centième image aussi facile que la première.
La méthode d'extraction qui convient dépend de votre travail. Pour des tâches à gros volume axées sur la cohérence — en particulier l'e-commerce et l'imagerie de produits intégrés à des tâches en aval comme les fiches produits et l'essayage virtuel — un outil dédié comme l'outil gratuit Image to Prompt d'Avriro vous donne des brouillons propres et standardisés à raffiner dans ChatGPT. Pour une analyse nuancée et exploratoire, la vision de ChatGPT seule peut suffire. Si vous hésitez encore entre les outils d'extraction en général, notre comparatif des meilleurs générateurs d'image to prompt pèse honnêtement les options.
Construisez le système une fois, et chaque image suivante vous le rembourse.