ai-tools
ChatGPTで画像からプロンプト生成:反復可能なワークフローを構築する
ChatGPTで画像からプロンプトを生成する方法を学びましょう。画像からプロンプトを抽出し、ビジョンの結果を改善し、時間を節約できる再利用可能なAIワークフローを構築します。

ほとんどの人は、ChatGPTのビジョン機能を遅い方法で使っています。画像をアップロードして“これを説明して”と入力し、段落が返ってきたら、次の画像でまた一からやり直すのです。これでも機能しますが、スケールしません。製品写真、デザインの参考画像、キャンペーンビジュアル、競合のクリエイティブなど、一日中画像を処理しているなら、その場しのぎのアプローチは静かに何時間も浪費し、一貫性のない結果を生み出します。
ChatGPTで画像からプロンプト生成がその解決策です。場当たり的なリクエストの代わりに、反復可能なシステムを構築します。画像から構造化されたプロンプトを抽出し、一貫した指示パターンでChatGPTに入力し、その出力を仕事全体で再利用するのです。このガイドでは、そのワークフローをゼロから設計する方法を紹介します。ChatGPTのビジョンが実際に反応する語彙、結果を再現可能にするテンプレート、そして自動化すべきか手動でプロンプトを書くべきかを判断するロジックです。これは、大量に処理し、一発芸ではなくシステムを求める人のために書かれています。
クイックアンサー
ChatGPTで画像からプロンプト生成とは、画像を構造化された再利用可能なテキストプロンプトに変換する手法です。ChatGPT自身のビジョンモデルに指示するか、まず専用の画像からプロンプト生成ツールを使うことで、ビジュアルを一貫して大規模に分析・説明・再現できます。中心的なメリットは反復可能性です。標準化されたプロンプト構造は、毎回異なる答えではなく、多数の画像にわたって比較可能な結果を生み出します。
目次
- ChatGPTで画像からプロンプト生成とは?
- ChatGPTが画像を理解する仕組み
- 手動でのプロンプト作成が大規模だと破綻する理由
- プロフェッショナルなワークフロー
- 実際のワークフロー例
- チーム別のユースケース
- プロンプトテンプレート(コピー&ペースト)
- より良いプロンプトのためのREFINEフレームワーク
- より良いChatGPTプロンプトのためのプロ向けテクニック
- プロンプトの品質を下げるミス
- よくある質問
- 重要なポイント
ChatGPTで画像からプロンプト生成とは?
ChatGPTで画像からプロンプト生成とは、視覚的な入力を、ChatGPT内で使える構造化されたテキストプロンプトに変換するあらゆるワークフローを指します。方法は2つあり、その違いを理解することがすべての基礎になります。
直接抽出。画像をChatGPT自体にアップロードし、そのビジョンモデルに特定の構造化された形式で説明するよう指示します。ChatGPTが分析とフォーマットを一度に行います。
ツール支援による抽出。まず画像を専用の画像からプロンプト生成ツール(Avriroの画像からプロンプト生成ツールなど)に通し、クリーンな構造化プロンプトを得ます。その後、そのプロンプトをChatGPTに持ち込んで、洗練・拡張・後続タスクに使います。
どちらが普遍的に優れているというわけではなく、それぞれ異なる状況に適しており、後ほど決定木で整理します。両者に共通するのは目標です。曖昧でその場限りのリクエストを、構造化された再利用可能な成果物に置き換えることです。その成果物こそが、スケール可能なワークフローの単位となります。
| 直接(ChatGPTビジョン) | ツール支援 | |
|---|---|---|
| 画像あたりの速度 | 遅い(毎回プロンプトを書く) | 速い(ワンクリック抽出) |
| 一貫性 | 指示次第 | 高い、標準化された出力 |
| コントロール | 完全 — 形式を自分で指示 | プリセット、その後ChatGPTで洗練 |
| 最適な用途 | ニュアンスのある単発の分析 | 大量で反復可能な作業 |
ChatGPTが画像を理解する仕組み
優れたワークフローを構築するには、ChatGPTが画像を“見る”ときに何が起きているかについて、実用的なメンタルモデルが必要です。そのビジョン機能は、OpenAIのドキュメントに記載されているように、視覚情報とテキスト情報を一緒に処理するマルチモーダルモデルによって支えられています。実用的には、その仕組みから3つのことが導かれます。
オブジェクトごとではなく、全体的に読み取ります。ChatGPTは単にオブジェクトを列挙するのではなく、関係性、スタイル、雰囲気、文脈を解釈します。だからこそ、画像が特定の印象を与える理由を説明するのが得意なのです。そして、あなたの指示は単なる目録ではなく、解釈を求めるべきなのです。
あなたの枠組みに従います。同じ画像でも、尋ね方によって出力は大きく変わります。“オブジェクトを列挙して”と“照明と構図を撮影ブリーフとして説明して”では、同一の写真に対して異なる分析が得られます。あなたの指示はレンズなのです。
隙間を埋めることがあり、実際に埋めます。すべてのビジョン言語モデルと同様に、ChatGPTは厳密には存在しない詳細を推測することがあります。もっともらしい素材や、想定された設定などです。これは創造的な拡張には役立ちますが、正確な説明には不利になります。だからこそ、検証は本格的なワークフローにおいて欠かせないステップなのです。
戦略的な意味合いはこうです。ChatGPTのビジョンは、あなたが与える構造の質を超えることはありません。曖昧な依頼は、曖昧で再現できない答えを生みます。構造化された指示は、構造化された再利用可能な答えを生みます。この構造こそ、このガイドの残りの部分で築き上げるものです。
手動でのプロンプト作成が大規模だと破綻する理由
各プロンプトを手書きするのは、1枚の画像なら問題なく機能します。しかし、量が絡んでくると予測どおりに破綻します。その理由はこうです。
- 一貫性のなさ。手書きの10個のプロンプトは10通りの異なる出力形式を生み、結果を比較したり後工程で一括処理したりすることが不可能になります。
- 認知的負荷。毎回ゼロから詳細で専門的な指示を作成するのは本当に疲れる作業で、長いセッションで疲労が蓄積すると品質が低下します。
- 失われる語彙。適切な描写用語(照明の方向、カメラアングル、素材、構図)はその場で思い出すのが難しく、手動のプロンプトは最も重要な詳細をまさに省いてしまいがちです。
- 再利用性のなさ。チャットウィンドウに入力して忘れられたその場限りのプロンプトは、再利用も、バージョン管理も、チームでの共有もできません。
- 時間コスト。大規模になると、画像あたりの数分が積み重なります。100枚の画像を手作業で処理するのは、1枚を処理するのとは次元の異なる問題です。
このパターンは、AI業務全般に現れるものと同じです。ボトルネックはモデルではなく、良い構造を一貫して供給する人間の能力なのです。その構造を(テンプレートや抽出ツールを通じて)体系化することこそ、優秀なモデルを生産的なワークフローに変えるものです。抽出のステップ自体が初めてなら、画像をAIプロンプトに変換する基礎から始めるとよいでしょう。
プロフェッショナルなワークフロー
これが反復可能なシステムです。5つの段階があり、その全体の目的は、視覚情報を使い捨ての答えではなく標準化された再利用可能な成果物に変換することです。
ステージ1 — 入力を標準化する。画像に触れる前に、望む形式を決めます。自然言語のブリーフ?構造化されたJSON?タグのリスト?一貫したターゲット形式こそが、出力を比較可能にします。
ステージ2 — 抽出する。画像をベースとなるプロンプトに変換します。大量処理には、専用ツールがワンクリックでクリーンで一貫した下書きを生成します。ニュアンスのある単発の場合は、標準の指示でChatGPTのビジョンに直接プロンプトを出します。
ステージ3 — ChatGPTで洗練する。ベースとなるプロンプトをChatGPTに持ち込み、素材として使います。拡張したり、ターゲットモデル向けに適応させたり、ブリーフに変換したり、バリエーションを生成したりします。ここがChatGPTの言語能力が最も価値を発揮する場面です。
ステージ4 — 検証する。出力を元の画像と照らし合わせて確認します。実際には存在しない推測された詳細を削除し、抽出が見落としたものを追加します。これは絶対に省略しないでください。幻覚による詳細に対するガードレールです。
ステージ5 — 保存して再利用する。完成したプロンプトを、わかりやすいラベルを付けてライブラリに保存します。再利用し、組み合わせ直します。プロジェクト全体の一貫性は、毎回書き直すのではなく、実証済みの構造を再利用することから生まれます。

これが機能する理由は、分析(ビジョンモデルや抽出ツールが最も得意)を、言語作業(ChatGPTが最も得意)や判断(あなたの役割)から切り離しているからです。各段階が1つのことをうまくこなすことで、システム全体が信頼でき、大量処理に耐えるほど高速になります。
実際のワークフロー例
これらは、その考え方がどう適用されるかを示す説明用のウォークスルーであり、スクリーンショットや実測されたケーススタディではありません。
例1 — 大規模なECの商品説明。ECチームは、数百枚の商品写真に対して一貫したSEO対応の説明文を必要としています。ワークフローはこうです。各商品画像から構造化されたプロンプトを抽出し、それを固定の指示とともにChatGPTに渡します。“この説明を使って、素材とユースケースを強調しながら、当社のブランドボイスで60語の商品紹介文を書いてください。”すべての画像が同じパイプラインに入るため、すべての出力が形式とトーンを共有します。これは公開ステップのための商品リスティングジェネレーターと自然に組み合わさります。
例2 — デザイン参考ブリーフ。デザイナーがムードボードの参考画像を集め、それぞれを明確なクリエイティブブリーフに変換する必要があります。ワークフローはこうです。スタイル、パレット、構図を捉えたプロンプトを抽出し、次にChatGPTに、雰囲気・色・レイアウトのセクションを持つ構造化されたブリーフとして再フォーマットするよう依頼します。その結果、すべての参考画像にわたって一貫したブリーフのテンプレートが得られ、チームやジェネレーターにそのまま渡せます。
例3 — モデル間のプロンプト適応。クリエイターが、ある画像のスタイルを別のジェネレーターで再現したいとします。ワークフローはこうです。ベースとなる説明を抽出し、次にChatGPTにターゲットシステム向けに適応させるよう依頼します。たとえば、Midjourneyが好む簡潔でカンマ重視のスタイルに変換します。Midjourneyで画像からプロンプト生成に関する当社のガイドで、そのターゲット固有の適応を詳しく解説しています。
例4 — 競合クリエイティブ分析。マーケティングエージェンシーが競合の広告ビジュアルをレビューします。ワークフローはこうです。それぞれの構造化された説明を抽出し、次にChatGPTに固定された軸(色の戦略、構図、感情的トーン)に沿って比較させ、漠然とした印象ではなく標準化された分析グリッドを生成します。
共通する筋道はこうです。いずれの場合も、上流での標準化された抽出こそが、ChatGPTの下流の出力を一貫性のある再利用可能なものにするのです。
チーム別のユースケース
- デザイナー — 参考画像をブリーフに変換し、シリーズ全体でスタイルの一貫性を維持します。
- ECチーム — 統一された構造で、写真から商品説明と代替テキストを一括生成します。
- コンテンツクリエイター — 視覚的なインスピレーションを、反復可能な出力のための再利用可能なプロンプトライブラリに変えます。
- マーケティングエージェンシー — クライアント全体で、競合クリエイティブ分析とキャンペーンのビジュアルブリーフを標準化します。
- プロンプトエンジニア — プロンプトテンプレートを構築・バージョン管理し、抽出をパイプラインの一ステップとして体系化します。
- AI愛好家 — 構造化された抽出結果を読み、編集することで描写の語彙を学びます。
プロンプトテンプレート(コピー&ペースト)
これらはオリジナルの再利用可能な指示テンプレートです。抽出した説明を、指定された箇所に貼り付けてください。
テンプレート1 — 構造化された画像ブリーフ
次の画像の説明を分析し、以下のセクションを持つ構造化されたブリーフを返してください:被写体、設定、照明、構図、カラーパレット、雰囲気、スタイル。具体的かつ簡潔に。説明:[PASTE]。
テンプレート2 — 画像からの商品紹介文
この商品説明を使って、[BRAND VOICE]のトーンで[WORD COUNT]語の商品紹介文を書いてください。素材、ユースケース、そして際立ったメリットを1つ強調してください。説明:[PASTE]。
テンプレート3 — モデル間の適応
この説明を、[TARGET MODEL]向けに最適化された簡潔でカンマ区切りのプロンプトに変換してください。被写体とスタイルを前方に配置し、[N]語以内に収めてください。説明:[PASTE]。
テンプレート4 — バリエーションジェネレーター
この説明を基に、同じ被写体とスタイルを保ちつつ、照明、カメラアングル、雰囲気を変えた5つのプロンプトのバリエーションを生成してください。説明:[PASTE]。
テンプレート5 — 正確性チェック
この説明を添付の画像と比較してください。説明に含まれるが画像には見えない詳細と、画像に見えるが説明が見落とした詳細をすべて列挙してください。説明:[PASTE]。
テンプレート5は、人々が省略しがちですが省略すべきでないものです。検証段階を実務に落とし込むものだからです。
より良いプロンプトのためのREFINEフレームワーク
抽出は下書きを与えてくれます。このフレームワーク、R-E-F-I-N-Eフレームワークと呼びますが、これは荒い下書きを高品質で再利用可能なプロンプトに変える方法です。これは、抽出したあらゆる説明に適用できるオリジナルの構造です。
- R — 削除幻覚による、または不正確な詳細を削除する(元画像と照合して検証する)。
- E — 強調目標にとって最も重要な要素を強調し、前方に配置する。
- F — フォーマット出力先に合わせて整形する(ブリーフ、タグ、カンマ重視のプロンプト、JSON)。
- I — 反復一度に1つの変数だけを変え、各変更の効果を切り分ける。
- N — 命名し、完成したプロンプトをライブラリに保存する。
- E — 評価出力を自分の意図と照らして評価し、必要ならテンプレートを洗練する。

このフレームワークの価値は、反復可能であることです。テンプレートとREFINEプロセスが一度整えば、100枚目の画像の処理は1枚目と同じくらい速く、一貫したものになります。それこそがワークフローの本質です。
より良いChatGPTプロンプトのためのプロ向けテクニック
- パイプライン向けに出力をJSONで標準化する。抽出結果がソフトウェアに入力されるなら、ChatGPTに固定キーの厳格なJSONを返すよう依頼します。予測可能な構造は、下流の自動化を簡単にします。
- その場限りのプロンプトではなく、テンプレートライブラリを構築する。コードをバージョン管理するように、指示テンプレートをバージョン管理します。再利用は再発明に勝ります。
- 分析と生成を分ける。画像に何があるかには抽出/ビジョンを使い、それをどうするかにはChatGPTを使います。1つの曖昧なプロンプトで両者を混ぜると、どちらも劣化します。
- 目立つ用語を前方に配置する。抽出もChatGPTも前方のコンテンツを重視します。重要なものから始めましょう。
- “ネガティブ”リストを持つ。自分の画像タイプでツールがよく幻覚する詳細を記録し、デフォルトで取り除きます。
- 抽出スタイルを出力先に合わせる。ブリーフやMidjourneyには自然言語を、SDXLにはタグを使います。あらゆる場面で1つの形式を押し通さないでください。
- 基礎を参照する。モデルを問わず適用できるプロンプト作成の原則については、コミュニティのPrompt Engineering GuideとOpenAIのプロンプトガイダンスが確かな参考資料です。
プロンプトの品質を下げるミス
- 抽出を最終形として扱う。下書きは素材であって、完成したプロンプトではありません。必ず洗練し、検証してください。
- 検証を省略する。幻覚による詳細は、源で捉えなければワークフロー全体に伝播します。
- 一貫性のない指示。画像ごとに異なる言い回しは、ワークフローを価値あるものにする比較可能性を損ないます。標準化してください。
- 1つのプロンプトに詰め込みすぎる。ChatGPTに分析、書き直し、適応を一度にすべて依頼すると、混乱した出力になります。段階を分けてください。
- 保存の仕組みがない。入力して忘れられたプロンプトは、ライブラリとして積み上がりません。良いものは保存しましょう。
- 出力先に合わない形式。ブリーフ形式の説明をタグベースのジェネレーターに無理やり押し込むと、性能が落ちます。形式をターゲットに合わせてください。
これらすべての背後にあるメタな間違いはこうです。システムを構築する代わりに、単一の出力を最適化してしまうこと。画像からプロンプト生成の作業の報酬は、1つの優れた説明ではありません。優れた説明を確実に生み出す反復可能なプロセスなのです。
よくある質問
ChatGPTで画像からプロンプト生成とは何ですか?
これは、画像を構造化された再利用可能なテキストプロンプトに変換する手法です。ChatGPTのビジョンモデルに指示するか、まず専用の抽出ツールを使うことで、ビジュアルを一貫して大規模に分析・再現できます。
ChatGPTは画像からプロンプトを生成できますか?
はい。画像をアップロードし、特定の構造化された形式でその写真を説明するよう指示します。品質は、指示がどれだけ構造化されているかに大きく左右されます。
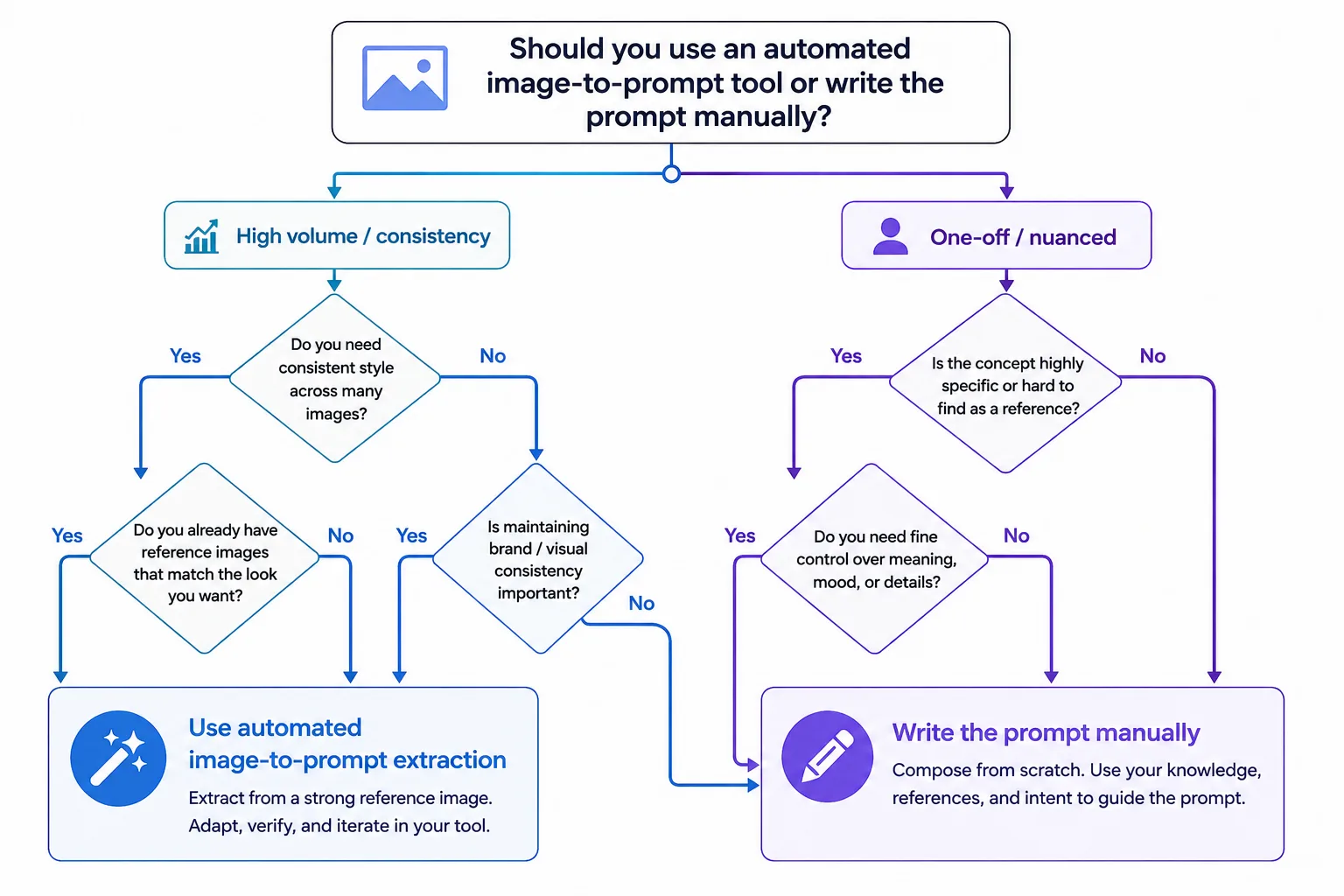
ChatGPTを直接使うべきですか、それとも専用ツールを使うべきですか?
完全なコントロールが欲しいニュアンスのある単発の分析にはChatGPTを直接使います。大量処理と一貫性には専用ツールを使い、その後ChatGPTで洗練します。上の決定木がこれを整理しています。
ChatGPTのビジョンは詳細を幻覚しますか?
ときにはあります。すべてのビジョン言語モデルと同様に、画像に存在しない詳細を推測することがあります。だからこそ、本格的なワークフローには検証ステップが不可欠なのです。
多数の画像にわたって出力を一貫させるにはどうすればよいですか?
指示テンプレートとターゲットの出力形式を標準化し、すべての画像を同じパイプラインに通します。一貫性はモデルからではなく、固定されたプロセスから生まれます。
これを大規模なECに使えますか?
はい。最も強力なユースケースの1つです。構造化された説明を抽出し、固定のブランドボイス指示とともにChatGPTに渡し、統一された商品コピーを生成します。
これとリバースプロンプトエンジニアリングの違いは何ですか?
両者は重なります。リバースプロンプトエンジニアリングは、具体的には画像を再現できるプロンプトを導き出すことを意味します。ChatGPTで画像からプロンプト生成はより広く、再現に加えて分析、説明、ワークフローのタスクも含みます。
始めるのにプロンプトエンジニアリングの知識は必要ですか?
いいえ。構造化された抽出結果を読み、編集すること自体が、語彙を素早く学ぶ方法です。ここにあるテンプレートは、事前の専門知識がなくても出発点を与えてくれます。
同じ指示は常に同じ結果を与えますか?
まったく同じにはなりません。言語モデルは出力にばらつきがあります。しかし、一貫したテンプレートは一貫した構造を生み出し、それこそがワークフローにとって重要なことです。
これは自動化されたパイプラインに入力できますか?
はい。ChatGPTに固定キーの厳格なJSONを返すよう依頼すれば、その構造化された出力が下流のソフトウェアを直接動かせます。
重要なポイント
ChatGPTで画像からプロンプト生成は、実のところどれか1枚の画像の話ではありません。視覚的な入力を、一枚ごとに時間を浪費することなく、一貫性のある再利用可能な出力に変えるシステムを構築することについての話です。ワークフローは分析、言語作業、判断を別々の段階に分けることで、それぞれを速く信頼できるものにし、テンプレートとREFINEフレームワークは100枚目の画像を1枚目と同じくらい楽にします。
どの抽出方法が合うかは、あなたの仕事次第です。大量で一貫性が求められる作業、特に商品リスティングやバーチャル試着のような下流タスクと統合されたECや商品画像には、無料のAvriroの画像からプロンプト生成ツールのような専用ツールが、ChatGPTで洗練するためのクリーンで標準化された下書きを提供します。ニュアンスのある探索的な分析には、ChatGPTのビジョン単体で十分かもしれません。まだ抽出ツール全般で迷っているなら、最高の画像からプロンプト生成ツールの比較で、選択肢を正直に検討しています。
システムを一度構築すれば、その後のすべての画像がそれを取り戻してくれます。